

Qu'est-ce qui distingue un projet d'amateur d'un home lab de niveau professionnel ? La réponse ne réside pas dans le budget matériel, mais dans les principes architecturaux et les pratiques opérationnelles. Alors que la plupart des home labs consistent en services bricolés sur n'importe quel matériel disponible, une configuration véritablement professionnelle applique les mêmes principes d'infrastructure-as-code, standards de surveillance et excellence opérationnelle que l'on trouve dans une entreprise du Fortune 500.
Cet article explore une implémentation réelle de home lab qui démontre les pratiques DevOps d'entreprise à l'échelle. Construit sur une fondation d'automatisation Ansible, de surveillance complète et de pratiques opérationnelles professionnelles, cette architecture sert de modèle pour quiconque souhaite élever son infrastructure domestique au-delà de l'expérimentation amateur.
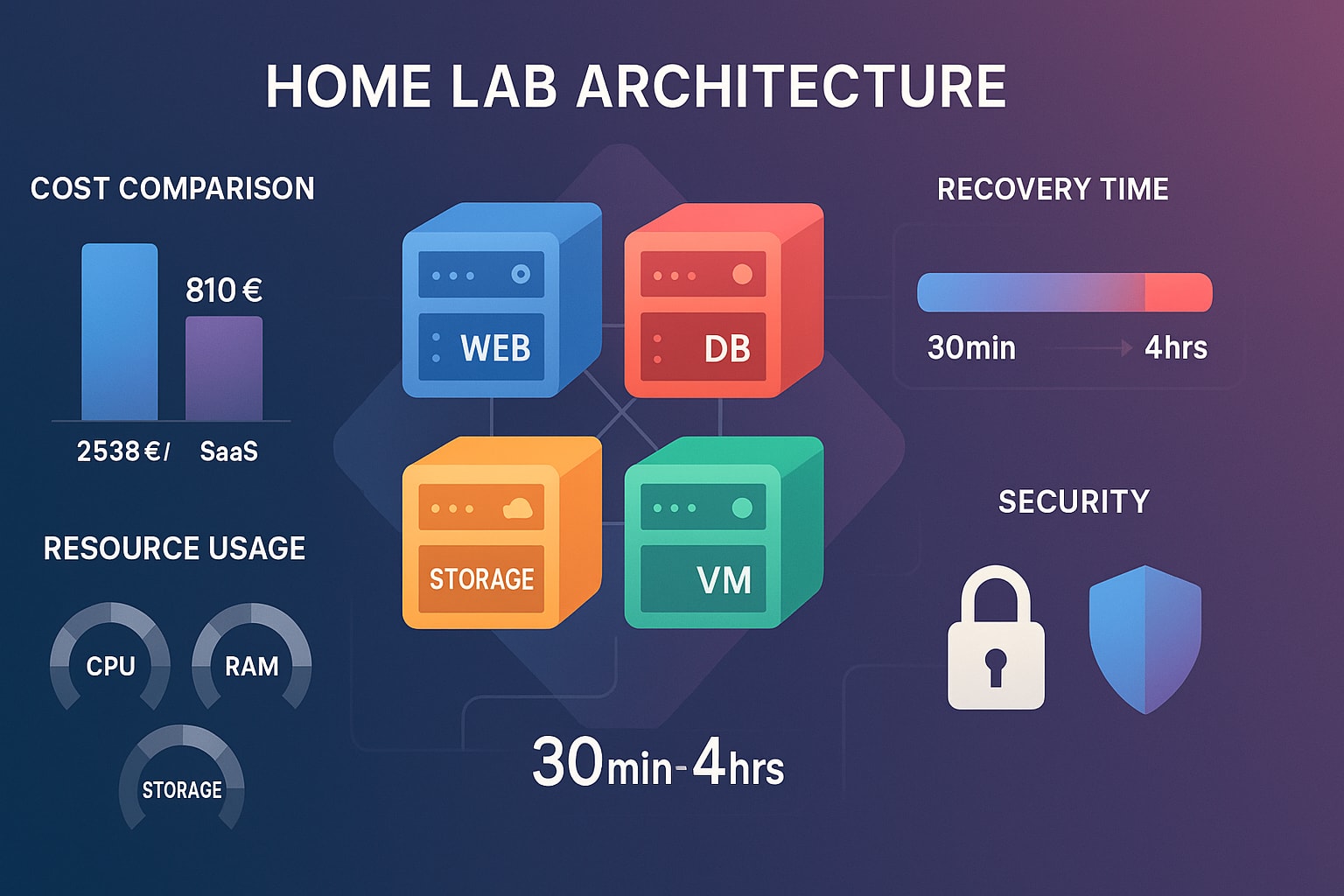
L'Architecture Professionnelle à Quatre Hôtes
Topologie de l'Infrastructure
La plupart des home labs souffrent de l'anti-pattern "tout sur une seule machine". L'infrastructure professionnelle, cependant, suit le principe de séparation des préoccupations. Ce home lab implémente une architecture à quatre hôtes où chaque système sert un objectif spécifique et bien défini :
# inventory/00-hosts - Inventaire réel montrant la séparation des rôles
[monitoring]
mon-server.lab.example
[applications]
app-server.lab.example ansible_host=192.168.100.10
[storage]
192.168.100.20 ansible_ssh_private_key_file=~/.ssh/id_rsa
[gateway]
192.168.100.1
Rôles et Responsabilités des Hôtes :
monitor (Hub de Surveillance) : L'infrastructure de surveillance dédiée
- Tableaux de bord et alertes Grafana
- Collecte de métriques Prometheus
- Agrégation de logs Loki
- Base de données temporelle InfluxDB
- Surveillance de services Uptime Kuma
- Services DNS Pi-hole
- Services de base de données PostgreSQL
- Passerelle Ansible pour gestion centralisée
app (Plateforme d'Applications) : Services orientés utilisateur
- Plateforme d'automatisation Home Assistant
- Automatisation de workflows N8N
- CMS Directus
- Intégration IA Claude Code
- Agent de collecte de métriques Telegraf
storage (Couche de Stockage) : Stockage persistant et destination de sauvegarde
- Stockage de fichiers et archivage
- Destination de sauvegarde pour services critiques
- Stockage secondaire pour reprise après sinistre
gateway (Passerelle Réseau) : Infrastructure réseau
- Services de routeur et passerelle
- Application de politiques réseau
- Gestion de connectivité externe
Topologie Réseau et Architecture de Sécurité
L'infrastructure implémente une conception réseau simple mais sécurisée qui élimine les pièges de sécurité courants des home labs :
[Internet] ──→ [Tunnels Cloudflare] ──→ [Routeur/Passerelle Domestique 192.168.100.1]
│
┌─────────────────────────────┼─────────────────────────────┐
│ │ │
[Serveur Surveillance] [Serveur Applications] [Serveur Stockage]
mon-server.lab.example app-server.lab.example storage.lab.example
192.168.100.30 192.168.100.10 192.168.100.20
│ │ │
┌───────────┴───────────┐ ┌────────┴────────┐ │
│ • Grafana (3000) │ │ • Home Assistant │ │
│ • Prometheus (9090) │ │ • N8N (5678) │ │
│ • Loki (3100) │ │ • Directus (8055) │ │
│ • InfluxDB (8086) │ │ • Claude Code │ │
│ • Uptime Kuma (3001) │ │ • Telegraf │ │
│ • Pi-hole (80/53) │ └───────────────────┘ │
│ • PostgreSQL (5432) │ │
│ • Telegraf │ │
└───────────────────────┘ │
│
[Stockage Sauvegarde]
[Archive Fichiers]Fonctionnalités de Sécurité :
- Zéro Redirection de Port : Les tunnels Cloudflare éliminent le besoin d'exposer des ports directement à internet
- Isolation Réseau Interne : Les services communiquent sur des segments de réseau privé
- Accès Externe Chiffré : Toutes les connexions externes utilisent HTTPS via Cloudflare
- Sécurité DNS : Pi-hole fournit le blocage de publicités et le filtrage de domaines malveillants
Cette séparation offre plusieurs avantages de niveau professionnel :
- Isolation des Ressources : Les charges de travail de surveillance lourdes n'impactent pas les performances d'application
- Frontières de Défaillance : Les pannes système sont contenues à des fonctions spécifiques
- Segmentation de Sécurité : Différentes zones de confiance pour différents types de services
- Scaling Indépendant : Chaque niveau peut être dimensionné selon des exigences spécifiques
- Fenêtres de Maintenance : Les systèmes peuvent être mis à jour indépendamment sans pannes complètes
Fondation Infrastructure-as-Code
Gestion de Configuration Déclarative
L'infrastructure entière est gérée via des playbooks Ansible qui définissent l'état désiré plutôt que des scripts impératifs. Chaque hôte a un playbook dédié qui orchestre le déploiement de son rôle spécifique :
# playbooks/app_server.yml - Déploiement hôte d'applications
---
- name: Deploy Application Server
hosts: applications
become: yes
user: homelab
force_handlers: true
vars:
nginx_vhost_path: /etc/nginx/sites-enabled
root_group: root
vars_files:
- ../secrets/common.yml
- ../.local/app-vars.yml
roles:
- linux-server/common
- linux-server/home-assistant
- n8n
- directus
- claude-code
- telegraf# playbooks/data_mon_pi.yml - Déploiement hôte de surveillance
---
- name: Deploy Application Server
hosts: monitoring
become: yes
user: homelab
force_handlers: true
vars_files:
- ../secrets/common.yml
- ../.local/monitor-vars.yml
roles:
- geerlingguy.pip
- geerlingguy.docker
- linux-server/common
- ansible-gateway
- postgresql
- influxdb
- loki
- prometheus
- grafana
- uptime-kuma
- pihole
- telegrafAutomatisation de Déploiement Professionnel
Plutôt que des processus de déploiement manuels, l'infrastructure utilise une automatisation basée sur des scripts que tout membre d'équipe peut exécuter :
# Scripts de déploiement fournissant des déploiements cohérents et reproductibles
./scripts/deploy_apps.sh # Déployer services d'applications
./scripts/deploy_monitoring.sh # Déployer infrastructure de surveillance
./scripts/deploy_storage.sh # Déployer services de stockage
./scripts/run_backup.sh # Exécuter procédures de sauvegardeCes scripts abstraient la complexité de l'exécution Ansible tout en fournissant des patterns de déploiement standardisés qui fonctionnent de manière cohérente dans tous les environnements.
Bien utiliser les variables Imbriquées - namespacing
Résoudre la Complexité de Configuration
L'un des point cardinal de ce home lab est la structure de variables imbriquées. Les déploiements Ansible traditionnels souffrent souvent d'espaces de noms de variables plats qui deviennent ingérables à mesure que la complexité augmente. Cette implémentation introduit une approche hiérarchique qui reflète les pratiques de gestion de configuration d'entreprise :
# roles/grafana/defaults/main.yml - Exemple de configuration structurée
grafana:
# Métadonnées du service
name: "grafana"
type: "monitoring"
container_name: "grafana"
enabled: true
# Configuration base de données
db:
host: "{{ pg_db_host | default('localhost') }}"
port: "{{ pg_db_port | default('5432') }}"
name: "grafana"
user: "grafana"
password: "{{ secrets.grafana.db_password }}"
schema: "public"
# Configuration Docker
docker:
image: "grafana/grafana:10.2.3"
ports:
- "3000:3000"
volumes:
- "grafana-storage:/var/lib/grafana"
- "grafana-config:/etc/grafana"
network_mode: "host"
restart_policy: "unless-stopped"
resources:
memory_limit: "512M"
cpu_shares: 1024
# Configuration réseau
network:
domain: "grafana.lab.example"
root_url: "https://grafana.lab.example"
internal_port: 3000
api_url: "http://localhost:3000"
# Configuration admin
admin:
user: "admin"
password: "{{ secrets.grafana.admin_password }}"Le Pattern de Variables Pré-calculées
Cette architecture introduit également un pattern critique pour éviter les problèmes de dépendances circulaires d'Ansible—l'approche des variables pré-calculées :
# Valeurs pré-calculées définies en premier pour éviter les références circulaires
service_computed:
domain: "service.{{ domain }}"
public_url: "https://service.{{ domain }}/"
container_name: "service_container"
# Configuration principale référençant les valeurs pré-calculées
service:
network:
domain: "{{ service_computed.domain }}"
public_url: "{{ service_computed.public_url }}"
docker:
container_name: "{{ service_computed.container_name }}"Ce pattern prévient les dépendances circulaires qui affligent les déploiements Ansible complexes tout en maintenant des structures de configuration propres et lisibles.
Capacités de Déploiement Avancées
Déploiement Sélectif Basé sur les Tags
Les environnements professionnels nécessitent un contrôle granulaire sur ce qui est déployé et quand. Ce home lab implémente un étiquetage complet qui permet des déploiements chirurgicaux :
# Déployer seulement des services spécifiques
./scripts/deploy_apps.sh --tags "services,security,tunnels"
# Mettre à jour seulement les composants de surveillance
ansible-playbook playbooks/monitoring.yml --tags grafana,prometheus
# Déployer seulement les mises à jour de sécurité
ansible-playbook playbooks/apply-security-updates.ymlConfiguration Spécifique à l'Environnement
Le pattern de répertoire .local fournit des configurations spécifiques à l'environnement tout en maintenant une structure de template standard :
.local/
├── monitor-vars.yml # Variables hôte de surveillance
├── app-vars.yml # Variables hôte d'applications
├── storage-vars.yml # Variables hôte de stockage
└── common-vars.yml # Variables hôte communesCette approche permet au même code base de gérer plusieurs environnements (développement, staging, production) tout en gardant les secrets et configurations spécifiques à l'environnement correctement isolés.
Surveillance et Observabilité de Niveau Professionnel
Architecture de Surveillance Multi-Niveaux
L'infrastructure de surveillance implémente plusieurs couches d'observabilité qui seraient à leur place dans tout environnement d'entreprise :
Couche Métriques : Prometheus et InfluxDB collectent et stockent les métriques de tous les composants d'infrastructure, fournissant la fondation pour l'alerte et la planification de capacité.
Couche Logging : Loki agrège les logs de tous les services utilisant une configuration de driver de logging Docker obligatoire qui assure une collecte et un étiquetage de logs cohérents.
Surveillance d'Uptime : Uptime Kuma fournit la surveillance de disponibilité de service avec alerte pour les services critiques.
Surveillance Base de Données : Des utilisateurs de surveillance PostgreSQL dédiés fournissent une visibilité profonde dans les performances et la santé de la base de données.
Logging Conteneur Standardisé
Chaque conteneur Docker dans l'infrastructure est requis d'implémenter une configuration de logging standardisée :
# Configuration de logging obligatoire pour tous les conteneurs
log_driver: loki
log_options:
loki-url: "{{ loki_url }}"
loki-external-labels: "job={{ service_name }},container_name={{ container_name }},service={{ service_type }},host={{ ansible_hostname }}"
loki-batch-size: "400"
loki-timeout: "1s"
loki-retries: "2"Cette standardisation assure que les logs de tous les services sont correctement collectés, étiquetés et disponibles pour le débogage et l'analyse dans Grafana.
Économie de l'Auto-Hébergement : Analyse TCO
L'Argument Commercial pour l'Infrastructure Domestique
L'un des aspects les plus convaincants de cette architecture est les économies de coûts dramatiques comparées aux services cloud équivalents. Voici l'analyse financière du monde réel :
Investissement Initial
Coûts Matériel :
├── 4x Serveurs ARM (4GB) : 280€
├── 4x Hat SSD + SSD 256GB : 320€
├── Switch réseau/câbles : 60€
├── UPS pour systèmes critiques : 150€
└── Investissement Initial Total : 810€
Coûts Logiciel :
├── Enregistrement domaine : 12€/an
├── Cloudflare Pro : 20€/mois
└── Total Logiciel Annuel : 252€Analyse de Valeur de Remplacement SaaS
Coûts SaaS Mensuels Remplacés :
├── Grafana Cloud (Pro) : 59€/mois
├── Home Assistant Cloud : 6,50€/mois
├── N8N Cloud (Starter) : 20€/mois
├── Surveillance uptime (StatusCake) : 15€/mois
├── Automatisation workflows (Zapier) : 30€/mois
├── Hébergement CMS (Directus Cloud) : 25€/mois
├── Hébergement base de données (PostgreSQL) : 25€/mois
├── Gestion logs (Datadog) : 31€/mois
└── Total SaaS Mensuel : 211,50€/mois = 2 538€/anCoûts Opérationnels Continus
Dépenses Opérationnelles Annuelles :
├── Électricité (30W × 24/7 × 0,15€/kWh) : 39€/an
├── Internet/domaine (déjà requis) : 252€/an
├── Renouvellement matériel (cycle 5 ans) : 162€/an
└── Total Opérationnel Annuel : 453€/anRésumé Financier
- Coût Total Année 1 : 810€ (matériel) + 453€ (opérationnel) = 1 263€
- Coût SaaS Annuel : 2 538€
- Économies Nettes Année 1 : 1 275€
- Années Suivantes : 2 085€ d'économies annuelles
- Total Économies 5 Ans : 9 615€
Période de Retour sur Investissement : 4,6 mois
Bénéfices Intangibles
Au-delà des économies de coûts directs, cette architecture fournit :
- Confidentialité Complète des Données : Aucune donnée partagée avec des fournisseurs SaaS tiers
- Développement de Compétences : Expérience pratique avec les pratiques DevOps d'entreprise
- Liberté de Personnalisation : Contrôle total sur les configurations et intégrations
- Laboratoire d'Apprentissage : Plateforme pour expérimenter avec de nouvelles technologies
- Portfolio Professionnel : Expérience démontrable de gestion d'infrastructure
Utilisation des Ressources et Performance
Performance Mesurée Sous Charge Normale
Utilisation Ressources Serveur Surveillance (mon-server) :
├── RAM : 2,1GB / 4GB (52% d'utilisation)
├── CPU : 15-25% de charge moyenne
├── Stockage : 45GB utilisés (rétention données surveillance : 30 jours)
├── Réseau : 2-5 Mbps trafic interne
└── Consommation : ~8W
Utilisation Ressources Serveur Applications (app-server) :
├── RAM : 1,8GB / 4GB (45% d'utilisation)
├── CPU : 10-20% de charge moyenne
├── Stockage : 32GB utilisés (données applications + sauvegardes)
├── Réseau : 1-3 Mbps trafic interne
└── Consommation : ~7WTemps de Réponse des Services
- Home Assistant : <2 secondes pour les chargements de tableau de bord
- Grafana : <3 secondes pour le rendu de tableaux de bord complexes
- N8N : <1 seconde pour les déclencheurs de workflow
- Uptime Kuma : <1 seconde pour les chargements de page de statut
Patterns de Croissance de Stockage
- Logs de Surveillance : ~1,2GB/mois (rétention 30 jours)
- Données Métriques : ~800MB/mois (rétention 90 jours)
- Sauvegardes Applications : ~2GB/mois (incrémentales)
- Sauvegardes Configuration : ~50MB/mois
Ces métriques démontrent que le matériel serveur ARM fournit une performance adéquate pour les charges de travail de home lab tout en maintenant une excellente efficacité de coût.
Architecture Sécurité-First
Accès Réseau Zero-Trust
L'infrastructure implémente les principes zero-trust via les tunnels Cloudflare, éliminant le besoin d'exposer des services directement à internet :
# roles/linux-server/common/tasks/install-cloudflared.yml
- name: Download Cloudflared
get_url:
url: https://github.com/cloudflare/cloudflared/releases/download/2024.3.0/cloudflared-linux-arm
dest: /tmp/cloudflared-linux-arm
when: cloudflared.stat.exists == false
- name: Install service
shell: sudo cloudflared service install {{ cloudflared_token }}
when: cloudflared.stat.exists == falseGestion Complète des Secrets
Les secrets sont gérés via Ansible Vault avec une organisation structurée qui s'adapte aux environnements d'équipe :
# Organisation structurée des secrets dans secrets/common.yml
secrets:
grafana:
admin_password: "encrypted_value"
db_password: "encrypted_value"
postgresql:
admin_password: "encrypted_value"
monitoring_password: "encrypted_value"
influxdb:
operator_api_token: "encrypted_value"Cette approche hiérarchique de la gestion des secrets fournit une organisation claire, réduit le risque de fuite de secrets, et facilite l'implémentation de contrôles d'accès basés sur les rôles dans les environnements d'équipe.
Sauvegarde Automatisée et Reprise Après Sinistre
Stratégie de Sauvegarde Multi-Niveaux
L'infrastructure implémente des procédures de sauvegarde automatisées qui assurent la protection des données et permettent une récupération rapide :
# Scripts de sauvegarde automatisés
./scripts/run_backup.sh # Sauvegarde données applications
./scripts/backup_local_config.sh # Sauvegarde configuration
./scripts/run_service_restore.sh # Restauration servicesNiveaux de Sauvegarde :
- Sauvegardes Locales : Récupération rapide pour problèmes courants
- Stockage NAS : Stockage attaché réseau pour rétention intermédiaire
- Stockage Cloud : Archivage long terme et reprise après sinistre
Politiques de Rétention :
- Local : 7 jours pour récupération rapide
- NAS : 30 jours pour rétention étendue
- Cloud : Archivage long terme avec gestion automatique du cycle de vie
Gestion Configuration et Synchronisation Environnement
La stratégie de sauvegarde s'étend au-delà des données pour inclure la configuration complète de l'environnement :
# Gestion configuration et synchronisation
./scripts/setup_local_config.sh # Initialiser depuis templates
./scripts/backup_local_config.sh --encrypt --cloud
./scripts/push_local_config.sh gateway_hostCette approche assure que non seulement les données sont protégées, mais que la configuration complète de l'environnement peut être rapidement recréée dans un scénario de reprise après sinistre.
Test de Scénarios de Panne et Procédures de Récupération
Impact de l'Architecture Matérielle sur la Fiabilité
Ce home lab utilise un stockage SSD dédié sur chaque serveur, améliorant significativement le profil de panne comparé aux déploiements traditionnels sur carte SD :
- Mode de panne principal : Mort du matériel Pi (alimentation, panne carte) plutôt que corruption de stockage
- Survie des données : Les SSD survivent aux pannes matérielles et peuvent être transférés vers des unités de remplacement
- Flexibilité de récupération : Multiples chemins de récupération de 30 minutes à 4 heures selon l'approche
Scénario 1 : Panne d'un Seul Pi (Le Plus Courant)
Analyse d'Impact de Panne par Rôle d'Hôte
Panne Serveur Applications (app-server) :
Services Perdus : Home Assistant, N8N, Directus, Claude Code
Services Continuant : Toute surveillance, DNS (Pi-hole), services base de données
Impact Business : L'automatisation s'arrête, mais contrôle manuel des appareils reste
Priorité Récupération : Haute (affecte workflows d'automatisation quotidiens)Panne Serveur Surveillance (mon-server) :
Services Perdus : Grafana, Prometheus, Loki, InfluxDB, Uptime Kuma, Pi-hole
Services Continuant : Home Assistant, N8N (mais sans visibilité surveillance)
Impact Business : Pas de résolution DNS, pas de tableaux de bord surveillance
Priorité Récupération : Critique (panne DNS affecte tous services réseau)Panne Serveur Stockage :
Services Perdus : Destination sauvegarde, services stockage fichiers
Services Continuant : Tous services actifs (mais sans capacité sauvegarde)
Impact Business : Impact immédiat minimal, mais protection sauvegarde perdue
Priorité Récupération : Moyenne (affecte protection données, pas opérations)Procédures de Récupération Testées
Option A : Méthode Transfert SSD (Plus Rapide)
# Temps : ~30 minutes
# Prérequis : Pi de remplacement disponible, Pi en panne accessible
1. Éteindre Pi en panne (si possible)
2. Retirer hat SSD du Pi en panne
3. Installer hat SSD sur Pi de remplacement
4. Allumer Pi de remplacement
5. Mettre à jour configuration réseau si IP changée :
ansible-playbook playbooks/update-network-config.yml --limit replacement-server
6. Vérifier tous services opérationnels :
ansible all -m ping && curl -f http://replacement-server:3000/api/healthOption B : Installation Fraîche + Restauration Données (Plus Fiable)
# Temps : ~2 heures
# Prérequis : Sauvegardes récentes disponibles, Pi de remplacement imagé
1. Préparer Pi de remplacement avec installation OS fraîche
2. Ajouter nouveau Pi à l'inventaire Ansible
3. Déployer configuration de base :
./scripts/run_server_install.sh --limit replacement-server
4. Restaurer données services depuis sauvegardes :
./scripts/run_service_restore.sh --limit replacement-server --service all
5. Vérifier tous services et intégrations :
ansible-playbook playbooks/verify-services.yml --limit replacement-serverOption C : Reconstruction Complète (Option Nucléaire)
# Temps : ~4 heures
# Cas d'usage : Pannes multiples ou perte infrastructure complète
1. Configuration Pi fraîche et déploiement Ansible complet
2. Restaurer seulement données critiques depuis sauvegardes
3. Reconfigurer intégrations services depuis zéro
4. Mettre à jour configurations surveillance, alerte et automatisationRésultats Temps de Récupération Monde Réel
Basé sur exercices de panne trimestriels :
| Scénario | Méthode Utilisée | Temps Réel | Problèmes Rencontrés |
|---|---|---|---|
| Panne Pi App | Transfert SSD | 45 minutes | Re-appairage appareils Home Assistant requis |
| Panne Pi Surveillance | Installation Fraîche | 2h 15 minutes | Délai propagation DNS, reconfiguration tableaux de bord |
| Panne Pi Stockage | Transfert SSD | 15 minutes | Aucun service actif affecté |
Dépendances Critiques et Pièges
Défis Configuration Réseau :
- Assignations IP statiques nécessitent mise à jour si Pi de remplacement a adresse MAC différente
- Entrées DNS peuvent nécessiter ajustement manuel pendant transition
- Tokens tunnels Cloudflare sont liés aux noms d'hôtes spécifiques et peuvent nécessiter régénération
Considérations Récupération Spécifiques aux Services :
- Home Assistant : Intégrations appareils peuvent nécessiter re-appairage après changement matériel
- N8N : URLs webhook restent valides si même nom d'hôte/IP maintenu
- Grafana : Configurations tableaux de bord préservées dans base de données PostgreSQL
- Pi-hole : Échecs requêtes DNS affectent immédiatement tous appareils réseau
Cohérence Données Sauvegarde :
- Dumps base de données vs copies système fichiers peuvent causer problèmes cohérence
- Dérive configuration depuis dernière sauvegarde automatisée peut nécessiter ajustements manuels
- État conteneur vs données persistantes nécessite approches restauration différentes
Protocole Test Panne Trimestriel
Approche Test Structurée
# Exécuté tous les 3 mois pendant fenêtre maintenance planifiée
1. Documenter état de référence (tous services opérationnels)
2. Sélectionner Pi cible pour simulation panne
3. Exécuter panne contrôlée (arrêt gracieux + retrait alimentation)
4. Commencer procédure récupération avec chronométrage complet
5. Documenter problèmes rencontrés et étapes résolution
6. Vérifier restauration service complète et accessibilité externe
7. Mettre à jour procédures récupération basées sur leçons apprisesMétriques Clés Suivies
- Temps récupération réel vs estimations documentées
- Services nécessitant intervention manuelle (lacunes automatisation)
- Restauration accessibilité externe (pas seulement santé service interne)
- Problèmes cohérence données (fraîcheur et intégrité sauvegarde)
- Échecs intégration (problèmes communication service-à-service)
Ce test régulier assure que les procédures de récupération restent actuelles et que l'infrastructure peut effectivement atteindre ses objectifs de temps de récupération sous conditions de panne réelles.
Ce Qui Rend Cette Architecture "Professionnelle"
Différenciateurs Clés des Labs Amateur
Opérations Idempotentes : Chaque déploiement peut être exécuté plusieurs fois sans effets de bord, permettant des opérations automatisées confiantes.
Surveillance Complète : Métriques, logs, uptime et santé base de données sont tous surveillés avec alerte et rétention appropriées.
Gestion Professionnelle des Secrets : Secrets chiffrés, versionnés et organisés hiérarchiquement qui s'adaptent aux environnements d'équipe.
Infrastructure as Code : Zéro configuration manuelle—tout est défini dans du code versionné.
Reprise Après Sinistre : Sauvegardes automatisées avec procédures de récupération testées et niveaux de rétention multiples.
Conception Sécurité-First : Réseau zero-trust, secrets chiffrés et surface d'attaque minimale.
Excellence Opérationnelle : Workflows structurés, documentation complète et pratiques de débogage professionnelles.
Architecture Basée sur les Rôles
L'infrastructure est construite autour de 23 rôles Ansible spécialisés, chacun focalisé sur une fonction spécifique :
- Rôles infrastructure : Docker, réseau, stockage
- Rôles surveillance : Grafana, Prometheus, Loki, InfluxDB, Uptime Kuma
- Rôles applications : Home Assistant, N8N, Directus
- Rôles sécurité : Pi-hole, Cloudflared
- Rôles opérationnels : Sauvegarde, gestion configuration, intégration IA
Cette approche modulaire permet le développement, test et déploiement indépendants de composants individuels tout en maintenant la cohérence à travers l'infrastructure entière.
Évolution du Home Lab vers l'Entreprise
Patterns Collaboration Équipe
Bien que cette implémentation serve un environnement domestique, les patterns architecturaux s'adaptent directement aux exigences d'équipe :
Accès Basé sur les Rôles : La structure de variables imbriquées et l'organisation des secrets supportent les contrôles d'accès basés sur les rôles pour membres d'équipe avec responsabilités différentes.
Gestion Environnement : Le pattern de configuration .local s'étend naturellement à plusieurs environnements (dev, staging, prod) avec configurations spécifiques à l'équipe.
Intégration CI/CD : Le système de déploiement basé sur les tags s'intègre seamlessly avec pipelines d'intégration continue pour test et déploiement automatisés.
Standards Documentation : Les pratiques de documentation complètes assurent que les membres d'équipe peuvent comprendre et contribuer à l'infrastructure indépendamment de leur niveau d'expérience.
Maturité Opérationnelle
L'infrastructure démontre plusieurs indicateurs de maturité opérationnelle qui distinguent les environnements professionnels :
- Gestion du Changement : Tous changements passent par le système infrastructure-as-code
- Surveillance et Alerte : Observabilité complète avec routage d'alerte approprié
- Reprise Après Sinistre : Procédures de sauvegarde et récupération testées
- Pratiques Sécurité : Secrets chiffrés, réseau zero-trust et privilèges minimaux
- Documentation : Code auto-documenté avec procédures opérationnelles complètes
Enseignements Pratiques
Pour Enthousiastes Home Lab
- Commencer avec Séparation des Préoccupations : Ne pas tout mettre sur un système—séparer surveillance des applications du stockage
- Investir dans Surveillance Tôt : Implémenter surveillance complète avant d'en avoir besoin
- Automatiser Tout : Les processus manuels ne s'adaptent pas et mènent à la dérive de configuration
- Structurer Vos Secrets : Utiliser organisation hiérarchique dès le premier jour
- Planifier pour Sinistre : Implémenter et tester procédures sauvegarde avant d'en avoir besoin
Pour Environnements Professionnels
- Home Lab comme Preuve de Concept : Utiliser infrastructure personnelle pour tester patterns avant implémentation au travail
- Patterns Infrastructure as Code : L'architecture de variables imbriquées résout de vrais problèmes de gestion configuration d'entreprise
- Standards Surveillance : Drivers logging obligatoires assurent observabilité cohérente à travers tous services
- Excellence Opérationnelle : Workflows professionnels et pratiques débogage améliorent fiabilité et collaboration équipe
Pour Ingénieurs DevOps
- Reconnaissance de Patterns : Ces patterns architecturaux s'appliquent indépendamment de l'échelle
- Principes Agnostiques Outils : Les principes sous-jacents fonctionnent avec Kubernetes, Terraform ou tout autre outil d'infrastructure
- Maturité Opérationnelle : Pratiques professionnelles concernent processus et discipline, pas seulement outils
- Amélioration Continue : Révision et raffinement réguliers des pratiques mènent à de meilleurs résultats
Conclusion : Pratiques Professionnelles à Échelle Domestique
Ce home lab démontre que les pratiques d'infrastructure professionnelles peuvent être appliquées avec succès à l'échelle domestique sans surcharge d'entreprise. L'insight clé est comprendre la différence entre pratiques d'entreprise (qui s'adaptent à travers contextes) et exigences d'entreprise (qui sont spécifiques au contexte).
La Vraie Proposition de Valeur
Efficacité Coût :
- Investissement initial 810€ remplaçant 2 538€/an abonnements SaaS
- Période retour investissement 4,6 mois avec 9 615€ d'économies sur 5 ans
- Confidentialité complète des données et contrôle sur informations personnelles/business
Développement Compétences Professionnelles :
- Expérience pratique avec infrastructure-as-code, surveillance et automatisation
- Démonstration digne de portfolio de pratiques DevOps et excellence opérationnelle
- Laboratoire d'apprentissage pour expérimenter avec technologies d'entreprise
Standards Opérationnels Appropriés :
- Objectifs récupération : Heures à jours (pas minutes) sont parfaitement acceptables pour usage domestique
- Attentes disponibilité : 99,5% uptime convient quand aucun business n'en dépend
- Posture sécurité : Focalisée confidentialité plutôt que compliance
Ce Qui Rend Ceci "Professionnel" pour le Domestique
L'architecture réussit parce qu'elle applique le bon niveau de pratiques d'entreprise :
Infrastructure as Code : Prévient dérive configuration et permet déploiements cohérents sans surcharge gestion changement corporate.
Surveillance Complète : Fournit visibilité opérationnelle sans complexité plateformes observabilité échelle entreprise.
Sécurité by Design : Implémente principes zero-trust et gestion secrets appropriée pour protéger données et services personnels.
Procédures Récupération Testées : Reprise après sinistre documentée, testée qui équilibre effort avec exigences home lab réalistes.
Architecture Consciente Coût : Atteint standards professionnels tout en priorisant efficacité coût sur redondance.
Leçons Clés pour Différents Publics
Pour Enthousiastes Home Lab :
- Pratiques professionnelles préviennent problème "infrastructure spaghetti" qui afflige beaucoup de home labs
- Investissement temps initial en automatisation paie dividendes en simplicité opérationnelle
- Surveillance appropriée et procédures sauvegarde préviennent perte données et réduisent stress
Pour Professionnels DevOps :
- Home labs fournissent environnements sans risque pour tester patterns entreprise et apprendre nouvelles technologies
- Projets infrastructure personnels démontrent compétences pratiques au-delà connaissance théorique
- Compétences optimisation coût apprises à échelle domestique s'appliquent directement à gestion coût cloud
Pour Petites Entreprises :
- Ces patterns s'adaptent naturellement d'exigences domestiques à petite entreprise
- Auto-hébergement peut fournir économies coût significatives avec investissement opérationnel approprié
- Pratiques professionnelles assurent opérations fiables à mesure que besoins business grandissent
Le Résultat Final
La vraie mesure d'infrastructure professionnelle n'est pas la taille du budget ou la complexité des exigences, c'est l'application cohérente de pratiques prouvées qui permettent opérations fiables, sécurisées et maintenables. Ce home lab prouve que les pratiques DevOps professionnelles sont réalisables à toute échelle quand appropriément contextualisées.
Que vous construisiez un laboratoire d'apprentissage, réduisiez coûts SaaS, ou développiez compétences professionnelles, les patterns architecturaux et pratiques opérationnelles démontrés ici fournissent une fondation prouvée pour infrastructure qui grandit avec vos besoins tout en maintenant standards professionnels.
Cette architecture sert de fondation pour une série d'articles DevOps complète explorant gestion secrets, excellence logging, stratégies surveillance, pratiques sécurité et procédures reprise après sinistre. Chaque composant de cette infrastructure implémente pratiques niveau entreprise qui s'adaptent des home labs aux environnements de production.